
gpt를 쓴지 생각보다는 꽤 오랜 시간이 지났다.
나는 친구비를 매달 주고 있는데, 처음에는 손 떨면서 결제했으나 지금은 옆에 둬야 마음이 편하달까..?
하지만 활용을 많이 못하고 있다는 생각이 들어 이 아이에 대해 좀 알아보려고 한다.
LLM이란?
Large Language Model (LLM) : 대규모 언어 모델
방대한 양의 텍스트 데이터로 훈련된 고급 AI 모델 이라고 한다.
그냥 쉽게 생각해서 완전 큰 데이터가 들어가있구나~ 하고 이해했다.
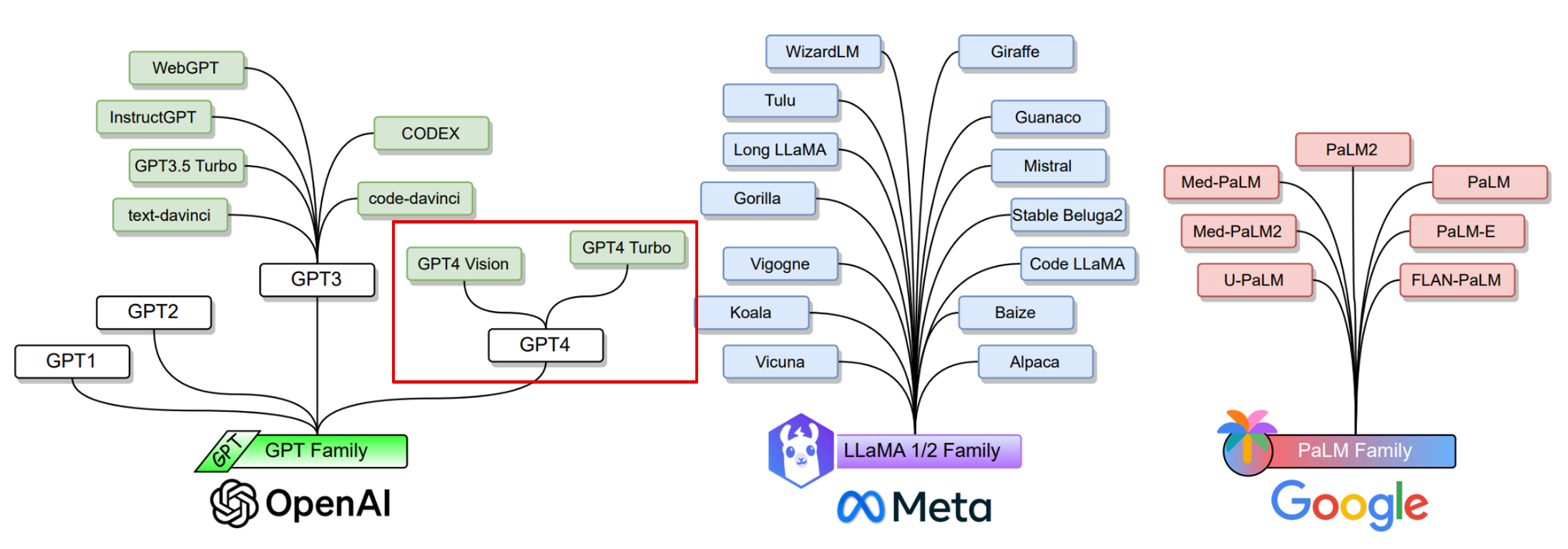
보통 AI 하면 GPT만 떠올리기 마련인데, 이렇게 다른 종류도 있다.
llama는 오픈소스인 장점이 있고, 구글꺼는 과거 Bard로 알려진 Gemini가 있다.
한국어 특화로는 클로바X가 있는데 요즘 한글 번역도 잘 해줘서 클로바는 아직 많이 안 써봤다.
Gemini가 좀 더 이미지 인식 등의 내용 이해를 잘 하고, 구글 다른 서비스들(유튜브, 지도 등)과 연동이 잘 된다고 한다.
GPT도 4까지는 조금 애매한 부분이 있었는데, 4o에서는 확실히 답변이 정확하고 상세해진 것 같다.
그럼 LLM은 어떻게 만들어지고 어떻게 최적화 되는지 알아보자.
LLM 개발 및 활용 단계
1. Pre-training
2. Fine-tuning
3. RAG (Retrieval Augmented Generation)
4. Prompt Engineering
- Pre-training (사전 학습):
- 설명: 대규모 언어 모델의 초기 학습 단계입니다. 이 단계에서는 모델이 방대한 양의 텍스트 데이터를 사용하여 언어의 구조와 패턴을 학습합니다. 주로 비지도 학습 방식으로 진행되며, 모델은 텍스트의 다음 단어를 예측하는 등의 작업을 통해 언어 모델을 학습합니다.
- 목적: 모델이 언어의 일반적인 패턴, 문법, 의미를 이해하도록 하기 위함입니다.
- Fine-tuning (미세 조정):
- 설명: 사전 학습이 완료된 모델을 특정 작업이나 도메인에 맞게 조정하는 단계입니다. 이 단계에서는 지도 학습 방식을 사용하여, 사전 학습된 모델에 추가적인 특정 데이터를 제공하여 모델의 성능을 향상시킵니다.
- 목적: 특정한 응용 분야에서 모델의 성능을 최적화하고, 더 구체적인 질문에 정확하게 답변할 수 있도록 합니다.
- RAG (Retrieval-Augmented Generation):
- 설명: 모델이 정보 검색과 생성 작업을 결합하여 응답을 생성하는 방법입니다. 모델은 먼저 주어진 질문에 대해 관련 정보를 검색한 다음, 검색된 정보를 바탕으로 답변을 생성합니다.
- 목적: 더 정확하고 정보에 기반한 응답을 생성하기 위함입니다. 특히, 최신 정보나 사전 학습 데이터에 포함되지 않은 정보를 제공할 때 유용합니다.
- Prompt Engineering (프롬프트 엔지니어링):
- 설명: LLM에 적절한 입력(프롬프트)을 제공하여 원하는 출력을 얻기 위해 프롬프트를 설계하고 최적화하는 과정입니다. 프롬프트의 구성과 표현 방식을 조정하여 모델이 원하는 방식으로 반응하도록 유도합니다.
- 목적: 모델이 특정한 방식으로 반응하거나, 더 나은 품질의 출력을 생성하도록 유도하기 위함입니다.
** 이 친구들은 어떻게 모델을 만들어놓고, 어떤 방식으로 질문하느냐에 따라 답변이 미세하게 달라진다.
그래서 프롬프트 엔지니어링이 중요한 것!! **
그럼 딥러닝의 분류 방식에 대해 아주 간단하게 이해해보자.

심플하게 보면 학습시킨 모델(분류 모델)을 통과하면서 어떤 조건인지 확인하고, 사과일 확률이 80%이므로 해당 값을 돌려주는 것이다.
그럼 이 분류 모델은 어떻게 만들어져있는지?
여기서부터는 살짝 멍해진다.
DL 인코더 & 디코더

딥러닝 레이어는 이런 형태로 많은 레이어 묶음으로 이루어져 있다.
각 레이어가 한 단계를 통과할 때마다, 벡터 차원으로 나오게 된다.
예를 들어, 사과 이미지가 주어지면 입력된 데이터와 동일하게 디코더로 사과 이미지가 다시 잘 복구되어 나오는지에 따라 데이터 컨트롤 능력이 좌우된다.

이 그림은 사과 대신 3 이미지를 예시로 든 것이다.
latent space에 3이라는 우리가 가진 데이터 점의 분포에 가깝다고 판단하여 동일하게 3이 나오는 것을 보여주는 것이다.
저 점이라는 벡터 사이 거리를 계산해서 거리가 가까우면 유사도가 높다고 판단하는 등, 모든 데이터는 벡터화가 되어 계산이 된다.
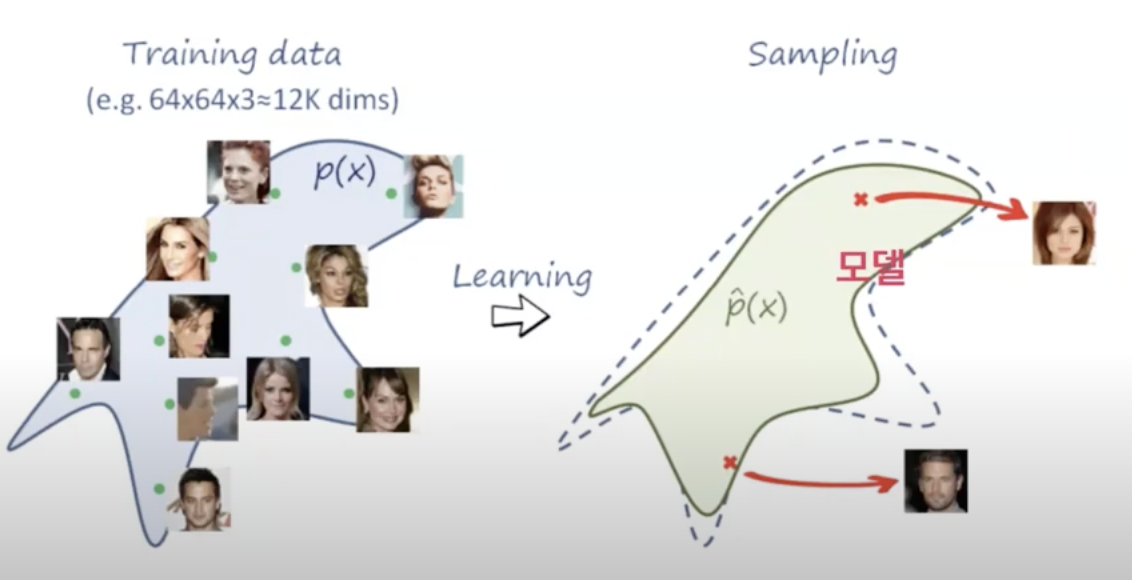
이런 식으로 사람 얼굴을 학습한다고 했을 때도 동일하게 점으로 표시하여 근사치로 유사도를 판단하게 되는 것이다.
NLP 자연어도 결국 벡터로 표현하여 나타낼 수 있다.
색상은 RGB 벡터로 표시하는 것처럼, 텍스트도 이런 식으로 벡터화 시키면 된다!

사이에 오는 단어를 찾기 위해서 다음과 같이 동작한다.

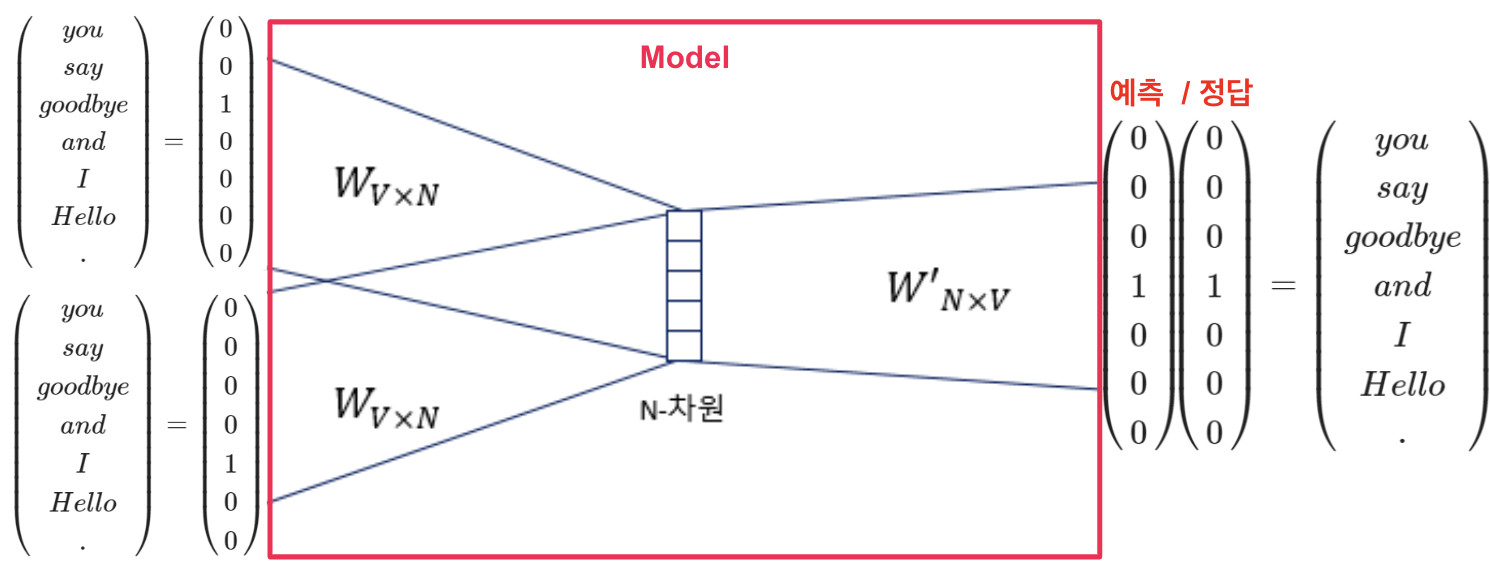
더 깊게 들어가면 끝도 없으니 간단하게 벡터화 시킨다는 개념만 알고 가면 앞으로도 훨씬 이해가 쉬울 것이다.
OpenAI Playground
를 이어서 하려다가 너무 길면 읽는 내가 졸리니까 이어서 글쓸 예정
'IT 기술 > AI' 카테고리의 다른 글
| [AI] AI 모델 테스트 및 레드팀의 필요성 (5) | 2024.09.17 |
|---|---|
| [AI] RAG (5) | 2024.09.13 |
| [AI] Chat API (3) | 2024.09.13 |
| [AI] ChatGPT, Bard, Claude, LLaMA 비교 (8) | 2024.09.12 |
| [AI] OpenAI Playground (3) | 2024.06.05 |